Background
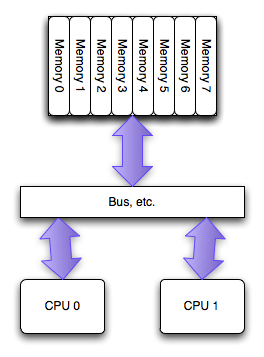
SMP and UMA
Traditionally, Symmetric Multi-Processing (SMP) systems were built upon a UMA architecture.
In this model, every CPU accesses the system memory through a shared system bus. The term “Uniform” implies that the access time to any memory location is the same for all processors, regardless of which memory module contains the data.
The Bottleneck: The Northbridge and FSB
Historically, all CPUs accessed memory via a dedicated chip called the Northbridge, which housed the Memory Controller. The CPUs connected to the Northbridge using the FSB (Front Side Bus).
However, this design had a critical flaw:
- Bus Contention: As the number of CPUs (or cores) increased, they all had to compete for the limited bandwidth of the single Front Side Bus.
- The “Memory Wall”: The Northbridge became a traffic bottleneck. No matter how fast the CPUs were, they spent a significant amount of time waiting for data to traverse the congested bus, severely limiting system scalability.
Enter NUMA
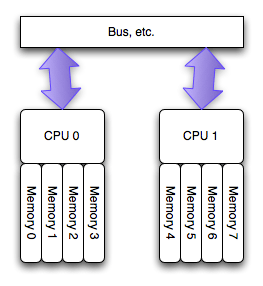
To eliminate the bottleneck of the shared FSB and Northbridge, the industry shifted to the NUMA architecture or called ccNUMA.
The Architectural Shift
In a NUMA system, the Memory Controller is moved from the external Northbridge directly inside the CPU package. This fundamental change leads to a decentralized memory architecture:
- Local Memory: Each CPU (or Socket) is physically connected to its own dedicated memory banks.
- Shared Address Space: Although memory is physically distributed, the hardware maintains a single, continuous memory address space. CPU A can still read data stored in CPU B’s memory.
Memory Access
The whole system may still operate as one unit, and all memory is basically accessible from everywhere, but at a potentially higher latency and lower performance.
The “Non-Uniform” in NUMA refers to the fact that memory access speed is no longer consistent; it depends on where the data is located relative to the CPU:
- Local Access (Fast): When a CPU accesses memory attached to its own controller. This path has high bandwidth and extremely low latency.
- Remote Access (Slow): When a CPU needs to access memory attached to another CPU. The data must travel over an interconnect bus (such as Intel QPI/UPI or AMD Infinity Fabric). This adds latency and consumes inter-socket bandwidth.
How Linux handles NUMA
Linux automatically understands when it’s running on a NUMA architecture system and does a few things:
- Enumerates the hardware to understand the physical layout.
- Divides the processors (not cores) into “nodes”. With modern PC processors, this means one node per physical processor, regardless of the number of cores present.
- Attaches each memory module in the system to the node for the processor it is local to.
- Collects cost information about inter-node communication (“distance” between nodes).
See how Linux enumerated your system’s NUMA layout using the numactl --hardware command.
NUMA changes things for Linux:
- each process and thread inherits, from its parent a NUMA poicy.
- scheduler attempts to ensure that evetry thread initially run on the preferred node.
- Memory allocated for the process is allocated on a particular node.
- Memory allocations made on one node will not be moved to another node.
The NUMA policy of any process can be changed(with numactl).
The problem
The Problem: Imbalanced Allocation & Swapping Database processes act as single, massive memory consumers. On NUMA systems, Linux’s default “Local Allocation” policy tries to stuff all memory requests into the node where the thread is running (e.g., Node 0). Consequence: Node 0 runs out of physical memory while Node 1 remains empty. This forces the OS to swap data on Node 0 to disk, causing severe performance degradation, even though the system has plenty of global free RAM.
The Solution: Interleaving The standard fix is to launch MySQL using numactl –interleave=all. Mechanism: This overrides the default policy and forces memory to be allocated in a Round-Robin fashion evenly across all NUMA nodes.
像MySQL这种外部请求随机性强,各个线程访问内存在地址上平均分布的这种应用,Interleave的内存分配模式相较默认模式可以带来一定程度的性能提升。 此外 各种 论文 中也都通过实验证实,真正造成程序在NUMA系统上性能瓶颈的并不是Remote Acess带来的响应时间损耗,而是内存的不合理分布导致Remote Access将inter-connect这个小水管塞满所造成的结果。而Interleave恰好,把这种不合理分布情况下的Remote Access请求平均分布在了各个小水管中。所以这也是Interleave效果奇佳的一个原因。
The Trade-off While interleaving sacrifices the slight latency benefit of local memory access, it eliminates the swapping bottleneck. For databases, the stability gained by avoiding disk I/O vastly outweighs the microsecond costs of remote memory access.
innodb_numa_interleave
从5.7开始,mysql增加了对NUMA的感知:innodb_numa_interleave
当开启了 innodb_numa_interleave 的话在为innodb buffer pool分配内存的时候将 NUMA memory policy 设置为 MPOL_INTERLEAVE 分配完后再设置回 MPOL_DEFAULT(OS默认内存分配行为,也就是zone_reclaim_mode指定的行为)。
innodb_numa_interleave参数是为innodb更精细化地分配innodb buffer pool 而增加的。很典型地innodb_numa_interleave为on只是更好地规避了前面所说的zone_reclaim_mode的kernel bug,kernel bug修复后这个参数没有意义了。
Linux 识别到 NUMA 架构后,默认的内存分配方案是优先分配远程内存
https://github.com/torvalds/linux/commit/4f9b16a64753d0bb607454347036dc997fd03b82
Link
summary:
https://blog.csdn.net/bandaoyu/article/details/122959097
problem(mysql):
https://blog.jcole.us/2010/09/28/mysql-swap-insanity-and-the-numa-architecture/